Spatial data in pytidycensus
![]()
This notebook demonstrates how to work with spatial data in pytidycensus, including creating maps and performing spatial analysis with GeoPandas.
Setup
First, let’s install and import the necessary packages:
# Uncomment to install if running in Colab
# !pip install pytidycensus geopandas matplotlib contextily
import pytidycensus as tc
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import warnings
warnings.filterwarnings('ignore')
# Set up matplotlib
plt.style.use('default')
%matplotlib inline
Census API Key Setup
Set your Census API key (get one at https://api.census.gov/data/key_signup.html):
# Replace with your actual API key
# tc.set_census_api_key("Your API Key Here")
Ignore the next cell. I am just loading my credentials from a yaml file in the parent directory.
import os
# Try to get API key from environment
api_key = os.environ.get("CENSUS_API_KEY")
# For documentation builds without a key, we'll mock the responses
try:
tc.set_census_api_key(api_key)
print("Using Census API key from environment")
except Exception:
print("Using example API key for documentation")
# This won't make real API calls during documentation builds
tc.set_census_api_key("EXAMPLE_API_KEY_FOR_DOCS")
Census API key has been set for this session.
Using Census API key from environment
Getting Spatial Data
When you set geometry=True in pytidycensus functions, the package automatically downloads the corresponding TIGER/Line shapefiles and merges them with your data.
Example: Median Household Income in Orange County, CA
Let’s get median household income for Census tracts in Orange County, California:
# Get ACS data with geometry for Orange County, CA
orange = tc.get_acs(
state="CA",
county="Orange",
geography="tract",
variables="B19013_001", # Median household income
geometry=True,
year=2022
)
print(f"Data type: {type(orange)}")
print(f"Shape: {orange.shape}")
print(f"CRS: {orange.crs}")
orange.head()
Getting data from the 2018-2022 5-year ACS
Data type: <class 'geopandas.geodataframe.GeoDataFrame'>
Shape: (613, 8)
CRS: EPSG:4269
| GEOID | geometry | B19013_001E | state | county | tract | NAME | B19013_001_moe | |
|---|---|---|---|---|---|---|---|---|
| 0 | 06059087404 | POLYGON ((-117.91667 33.82542, -117.91292 33.8... | 66691 | 06 | 059 | 087404 | Orange County, California | 9993.0 |
| 1 | 06059011502 | POLYGON ((-117.89832 33.87416, -117.88963 33.8... | 65625 | 06 | 059 | 011502 | Orange County, California | 27504.0 |
| 2 | 06059075812 | POLYGON ((-117.83579 33.81248, -117.83327 33.8... | 91353 | 06 | 059 | 075812 | Orange County, California | 4602.0 |
| 3 | 06059110606 | POLYGON ((-118.01147 33.88085, -118.00275 33.8... | 83813 | 06 | 059 | 110606 | Orange County, California | 13677.0 |
| 4 | 06059011000 | POLYGON ((-117.96816 33.87231, -117.9682 33.87... | 102250 | 06 | 059 | 011000 | Orange County, California | 40329.0 |
The returned object is a GeoDataFrame with a geometry column containing the spatial boundaries. The default coordinate system is NAD83 (EPSG:4269).
Basic Choropleth Mapping
Let’s create a basic choropleth map:
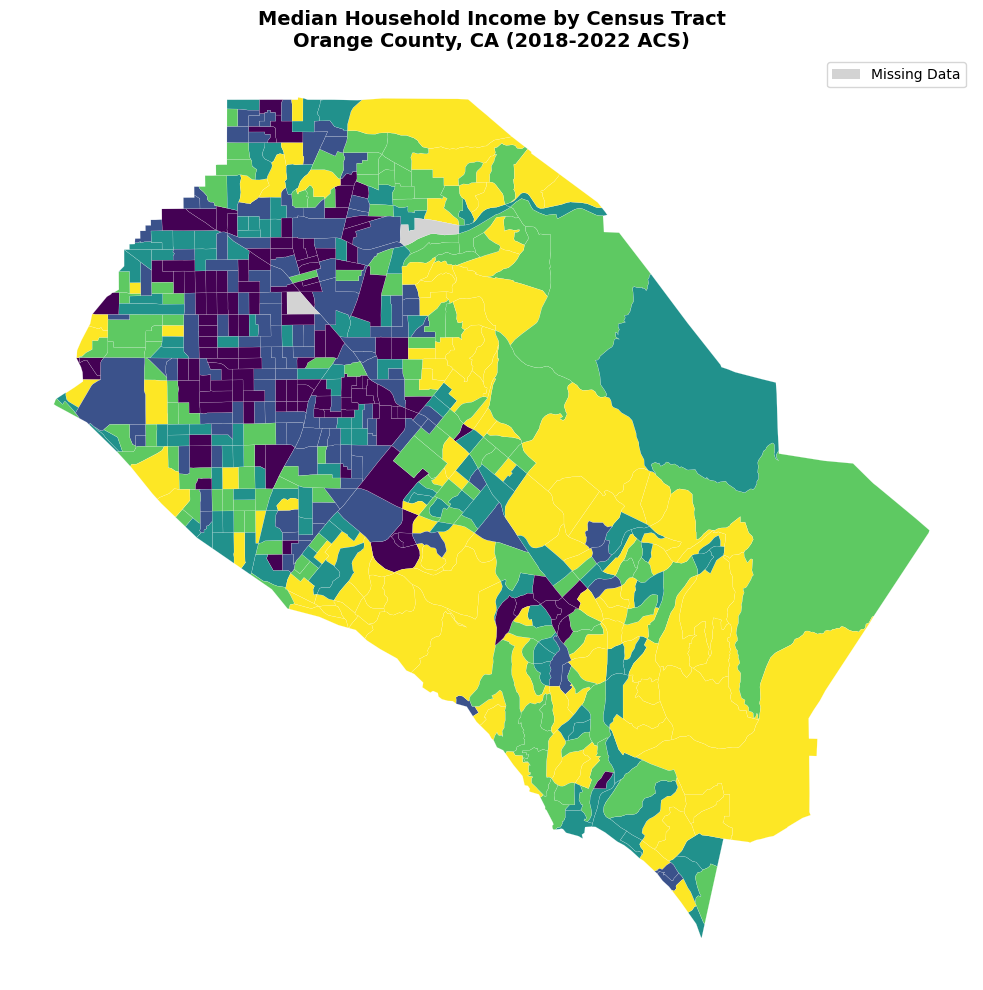
# Create a basic choropleth map with missing data highlighted
fig, ax = plt.subplots(figsize=(12, 10))
# Create a mask for missing values
missing_mask = orange["B19013_001E"].isna()
# Plot non-missing data with color scheme
orange[~missing_mask].plot(
column="B19013_001E",
cmap="viridis",
linewidth=0.1,
edgecolor="white",
legend=True,
ax=ax,
scheme="quantiles", # or "equal_interval"
k=5,
)
# Plot missing data with distinct color
orange[missing_mask].plot(
color="lightgray", # or any color for missing data
linewidth=0.1,
edgecolor="white",
ax=ax,
)
ax.set_title(
"Median Household Income by Census Tract\nOrange County, CA (2018-2022 ACS)",
fontsize=14,
fontweight="bold",
)
ax.set_axis_off()
# Add missing data to legend
from matplotlib.patches import Patch
handles, labels = ax.get_legend_handles_labels()
handles.append(Patch(facecolor="lightgray", label="Missing Data"))
ax.legend(handles=handles, loc="upper right")
plt.tight_layout()
plt.show()
Coordinate Reference Systems
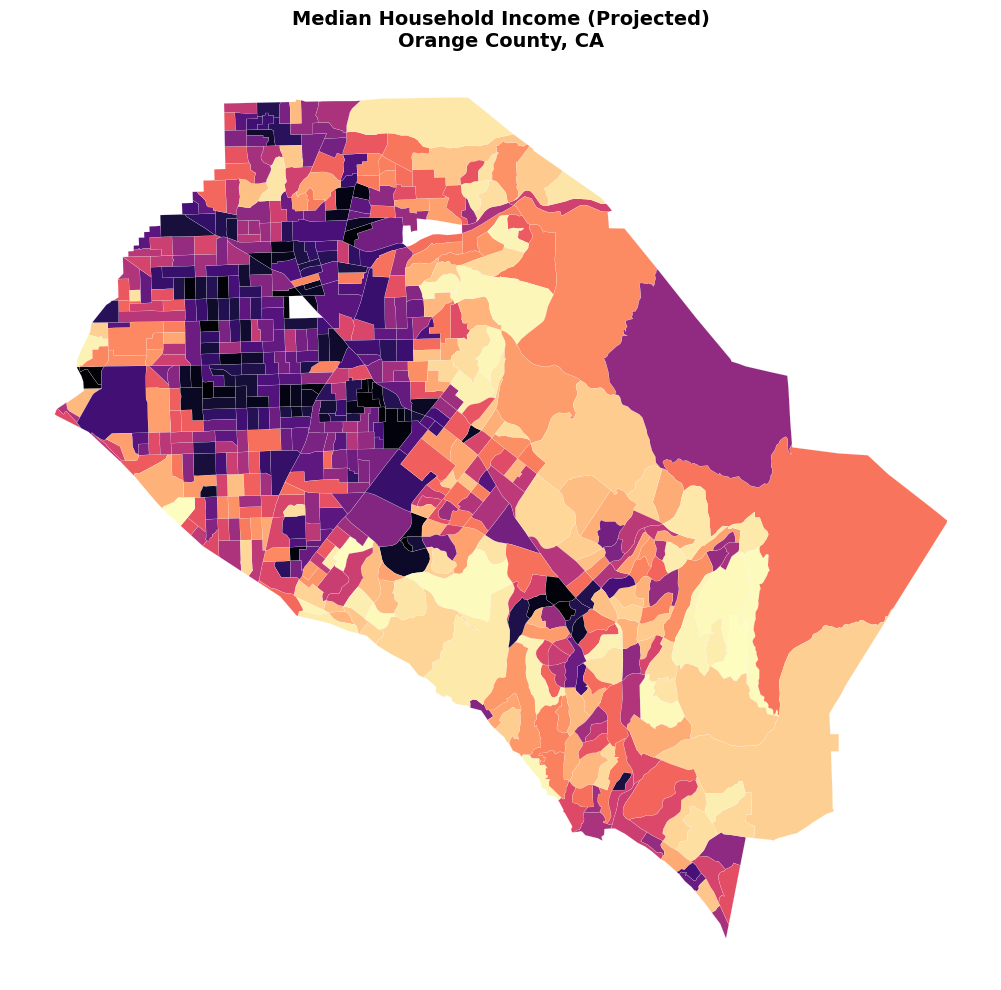
For better visualization and analysis, it’s often useful to project the data to an appropriate coordinate system:
# Project to California Albers (EPSG:3310) for better area representation
orange_projected = orange.to_crs('EPSG:3310')
fig, ax = plt.subplots(figsize=(12, 10))
orange_projected.plot(
column="B19013_001E",
cmap="magma",
linewidth=0.1,
edgecolor="white",
legend=False,
ax=ax,
)
ax.set_title('Median Household Income (Projected)\nOrange County, CA',
fontsize=14, fontweight='bold')
ax.set_axis_off()
plt.tight_layout()
plt.show()
Faceted Mapping
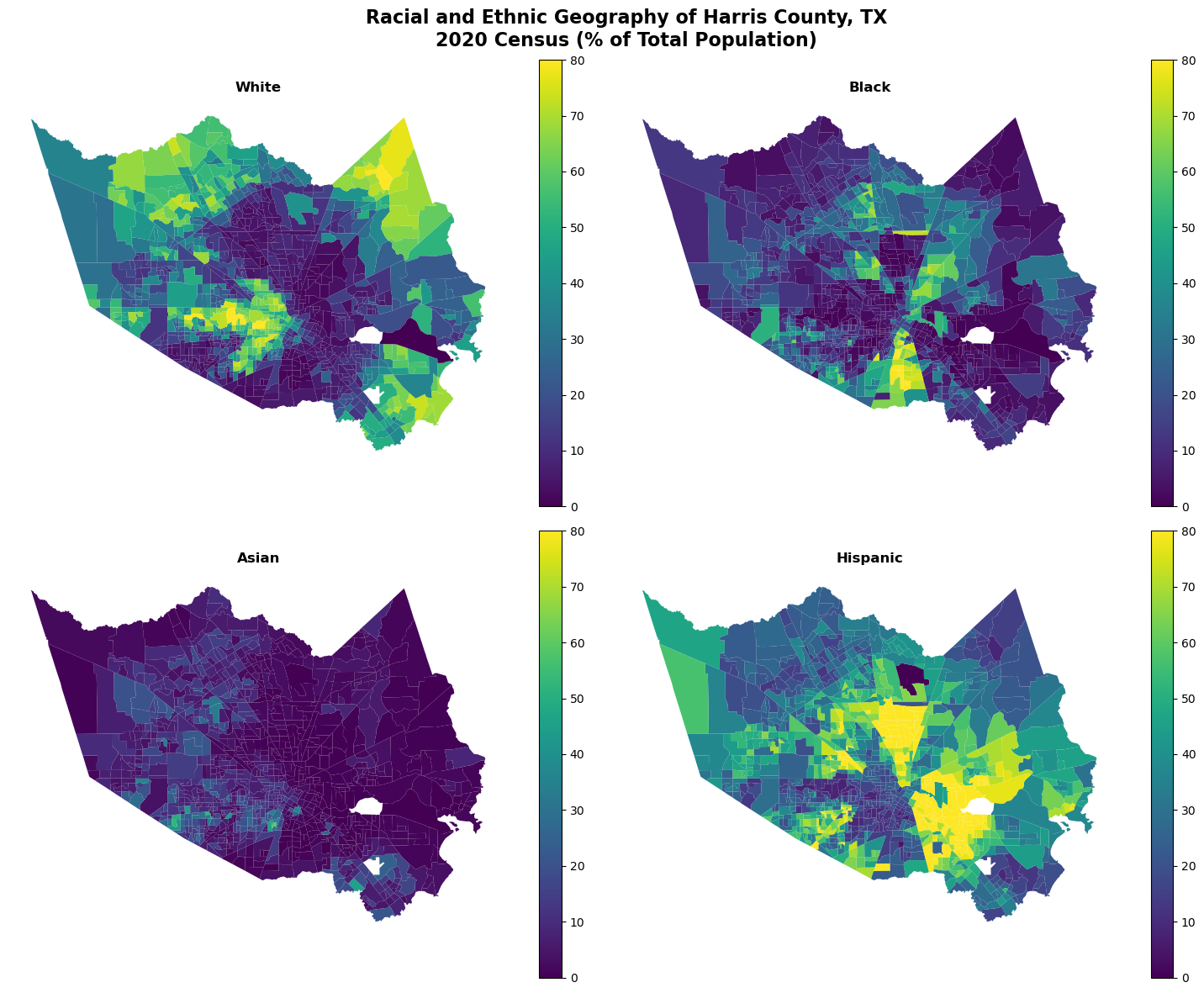
One powerful feature is creating small multiples to compare different variables. Let’s look at racial demographics in Harris County, Texas.
Race/Ethnicity Data with Summary Variable
# Define race/ethnicity variables for 2020 Census
race_vars = {
"White": "P2_005N",
"Black": "P2_006N",
"Asian": "P2_008N",
"Hispanic": "P2_002N"
}
# Get data for Harris County, TX with total population as summary variable
harris = tc.get_decennial(
geography="tract",
variables=race_vars,
state="TX",
county="Harris",
geometry=True,
summary_var="P2_001N", # Total population
year=2020,
sumfile="pl",
output='tidy'
)
print(f"Shape: {harris.shape}")
harris.head()
Getting data from the 2020 decennial Census
Using the PL 94-171 Redistricting Data Summary File
Shape: (4460, 13)
| GEOID | NAME_x | geometry | STATEFP | COUNTYFP | TRACTCE | state | county | tract | NAME_y | variable | estimate | summary_est | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 48201530200 | 5302 | POLYGON ((-95.45086 29.81984, -95.44872 29.819... | 48 | 201 | 530200 | 48 | 201 | 530200 | Harris County, Texas | White | 2057 | 3766 |
| 1 | 48201530200 | 5302 | POLYGON ((-95.45086 29.81984, -95.44872 29.819... | 48 | 201 | 530200 | 48 | 201 | 530200 | Harris County, Texas | Black | 127 | 3766 |
| 2 | 48201530200 | 5302 | POLYGON ((-95.45086 29.81984, -95.44872 29.819... | 48 | 201 | 530200 | 48 | 201 | 530200 | Harris County, Texas | Asian | 239 | 3766 |
| 3 | 48201530200 | 5302 | POLYGON ((-95.45086 29.81984, -95.44872 29.819... | 48 | 201 | 530200 | 48 | 201 | 530200 | Harris County, Texas | Hispanic | 1154 | 3766 |
| 4 | 48201534002 | 5340.02 | POLYGON ((-95.51398 29.92533, -95.50999 29.925... | 48 | 201 | 534002 | 48 | 201 | 534002 | Harris County, Texas | White | 388 | 5653 |
Notice that we have multiple rows per tract (one for each race/ethnicity variable) and a summary_value column with the total population.
Calculate Percentages and Create Faceted Map
# Calculate percentage of total population
harris["percent"] = 100 * (harris["estimate"] / harris["summary_est"])
harris.head()
| GEOID | NAME_x | geometry | STATEFP | COUNTYFP | TRACTCE | state | county | tract | NAME_y | variable | estimate | summary_est | percent | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 48201530200 | 5302 | POLYGON ((-95.45086 29.81984, -95.44872 29.819... | 48 | 201 | 530200 | 48 | 201 | 530200 | Harris County, Texas | White | 2057 | 3766 | 54.620287 |
| 1 | 48201530200 | 5302 | POLYGON ((-95.45086 29.81984, -95.44872 29.819... | 48 | 201 | 530200 | 48 | 201 | 530200 | Harris County, Texas | Black | 127 | 3766 | 3.372278 |
| 2 | 48201530200 | 5302 | POLYGON ((-95.45086 29.81984, -95.44872 29.819... | 48 | 201 | 530200 | 48 | 201 | 530200 | Harris County, Texas | Asian | 239 | 3766 | 6.346256 |
| 3 | 48201530200 | 5302 | POLYGON ((-95.45086 29.81984, -95.44872 29.819... | 48 | 201 | 530200 | 48 | 201 | 530200 | Harris County, Texas | Hispanic | 1154 | 3766 | 30.642592 |
| 4 | 48201534002 | 5340.02 | POLYGON ((-95.51398 29.92533, -95.50999 29.925... | 48 | 201 | 534002 | 48 | 201 | 534002 | Harris County, Texas | White | 388 | 5653 | 6.863612 |
# Create faceted map
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
axes = axes.ravel()
# Get unique variables for iteration
variables = harris['variable'].unique()
for i, var in enumerate(variables):
# Filter data for this variable
subset = harris[harris['variable'] == var]
# Create map
subset.plot(
column='percent',
cmap='viridis',
linewidth=0,
legend=True,
ax=axes[i],
vmin=0,
vmax=80 # Set consistent scale
)
axes[i].set_title(f'{var}', fontsize=12, fontweight='bold')
axes[i].set_axis_off()
plt.suptitle('Racial and Ethnic Geography of Harris County, TX\n2020 Census (% of Total Population)',
fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()
Interactive Analysis
Let’s explore the data interactively by looking at summary statistics:
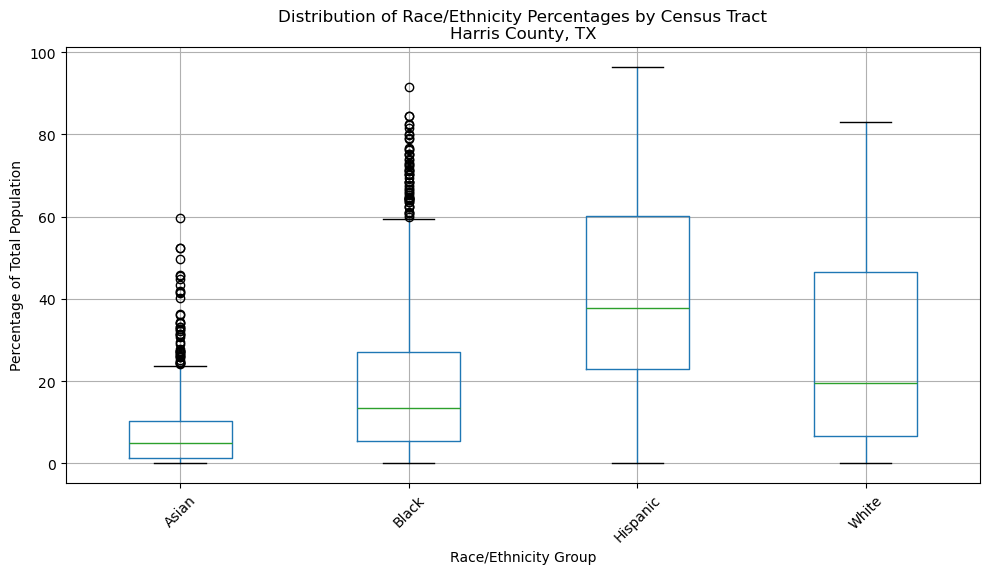
# Summary statistics by race/ethnicity
summary_stats = harris.groupby('variable')['percent'].describe()
print("Percentage Distribution by Race/Ethnicity:")
print(summary_stats.round(2))
Percentage Distribution by Race/Ethnicity:
count mean std min 25% 50% 75% max
variable
Asian 1113.0 7.27 8.11 0.0 1.29 4.82 10.37 59.71
Black 1113.0 19.19 18.12 0.0 5.36 13.35 27.14 91.57
Hispanic 1113.0 43.02 23.88 0.0 22.84 37.65 60.16 96.52
White 1113.0 27.14 22.76 0.0 6.67 19.54 46.49 82.94
# Create box plots to show distribution
fig, ax = plt.subplots(figsize=(10, 6))
harris.boxplot(column='percent', by='variable', ax=ax)
ax.set_title('Distribution of Race/Ethnicity Percentages by Census Tract\nHarris County, TX')
ax.set_xlabel('Race/Ethnicity Group')
ax.set_ylabel('Percentage of Total Population')
plt.xticks(rotation=45)
plt.suptitle('') # Remove automatic title
plt.tight_layout()
plt.show()
Working with Different Geographic Levels
State-Level Data
Let’s create a map of median household income for all US states:
# Get median household income for all states
states_income = tc.get_acs(
geography="state",
variables="B19013_001",
year=2022,
geometry=True
)
states_income.head()
Getting data from the 2018-2022 5-year ACS
| GEOID | geometry | STUSPS | B19013_001E | state | NAME | B19013_001_moe | |
|---|---|---|---|---|---|---|---|
| 0 | 35 | POLYGON ((-109.05017 31.48, -109.04984 31.4995... | NM | 58722 | 35 | New Mexico | 581.0 |
| 1 | 46 | POLYGON ((-104.05788 44.9976, -104.05078 44.99... | SD | 69457 | 46 | South Dakota | 788.0 |
| 2 | 06 | MULTIPOLYGON (((-118.60442 33.47855, -118.5987... | CA | 91905 | 06 | California | 277.0 |
| 3 | 21 | MULTIPOLYGON (((-89.40565 36.52816, -89.39868 ... | KY | 60183 | 21 | Kentucky | 443.0 |
| 4 | 01 | MULTIPOLYGON (((-88.05338 30.50699, -88.05109 ... | AL | 59609 | 01 | Alabama | 377.0 |
# Remove territories for cleaner continental US map
states_continental = states_income[
~states_income["NAME"].isin(
[
"Puerto Rico",
"United States Virgin Islands",
"Guam",
"American Samoa",
"Commonwealth of the Northern Mariana Islands",
]
)
]
print(f"Number of states/DC: {len(states_continental)}")
Number of states/DC: 51
# Project to Albers Equal Area for US mapping
states_albers = states_continental.to_crs('EPSG:5070')
fig, ax = plt.subplots(figsize=(15, 10))
states_albers.plot(
column="B19013_001E",
cmap="RdYlBu_r",
linewidth=0.5,
edgecolor="white",
legend=True,
ax=ax,
)
ax.set_title('Median Household Income by State\n2018-2022 American Community Survey',
fontsize=16, fontweight='bold')
ax.set_axis_off()
# Add colorbar label
cbar = ax.get_figure().get_axes()[1]
cbar.set_ylabel('Median Household Income ($)', rotation=270, labelpad=20)
plt.tight_layout()
plt.show()
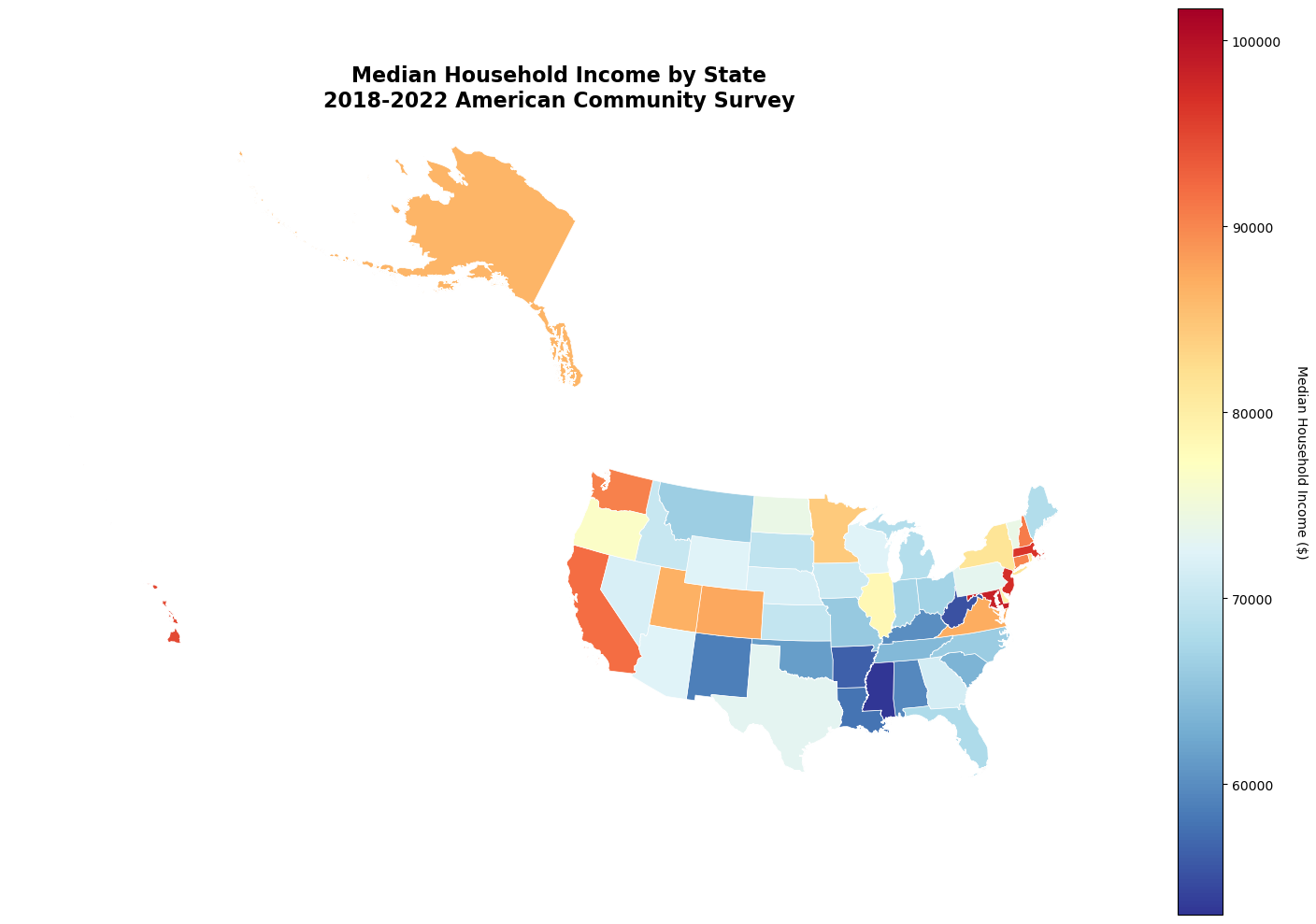
County-Level Analysis
Let’s look at population density across counties in a specific state:
# Get population and calculate density for California counties
ca_counties = tc.get_acs(
geography="county",
variables="B01003_001", # Total population
state="CA",
year=2022,
geometry=True
)
ca_counties.head()
Getting data from the 2018-2022 5-year ACS
| GEOID | geometry | NAMELSAD | B01003_001E | state | county | NAME | B01003_001_moe | |
|---|---|---|---|---|---|---|---|---|
| 0 | 06037 | MULTIPOLYGON (((-118.60442 33.47855, -118.5987... | Los Angeles County | 9936690 | 06 | 037 | Los Angeles County, California | <NA> |
| 1 | 06097 | POLYGON ((-123.53354 38.76841, -123.52851 38.7... | Sonoma County | 488436 | 06 | 097 | Sonoma County, California | <NA> |
| 2 | 06001 | POLYGON ((-122.34225 37.80556, -122.33385 37.8... | Alameda County | 1663823 | 06 | 001 | Alameda County, California | <NA> |
| 3 | 06045 | POLYGON ((-124.02325 40.00128, -123.93545 40.0... | Mendocino County | 91145 | 06 | 045 | Mendocino County, California | <NA> |
| 4 | 06015 | MULTIPOLYGON (((-124.2175 41.95081, -124.21704... | Del Norte County | 27462 | 06 | 015 | Del Norte County, California | <NA> |
# Calculate area in square kilometers and population density
ca_counties_proj = ca_counties.to_crs('EPSG:3310') # California Albers
ca_counties_proj['area_km2'] = ca_counties_proj.geometry.area / 1e6
ca_counties_proj["density"] = (
ca_counties_proj["B01003_001E"] / ca_counties_proj["area_km2"]
)
print("Top 10 most dense counties:")
print(ca_counties_proj.nlargest(10, 'density')[['NAME', 'density']].round(1))
Top 10 most dense counties:
NAME density
47 San Francisco County, California 6947.7
30 Orange County, California 1535.7
0 Los Angeles County, California 937.5
2 Alameda County, California 856.2
24 San Mateo County, California 636.3
54 Sacramento County, California 613.2
36 Contra Costa County, California 590.4
32 Santa Clara County, California 569.2
23 San Diego County, California 298.3
40 Santa Cruz County, California 232.2
# Map population density with log scale
fig, ax = plt.subplots(figsize=(12, 15))
# Use log scale for better visualization of density
ca_counties_proj['log_density'] = np.log10(ca_counties_proj['density'] + 1)
ca_counties_proj.plot(
column='log_density',
cmap='OrRd',
linewidth=0.2,
edgecolor='white',
legend=True,
ax=ax
)
ax.set_title('Population Density by County\nCalifornia (Log Scale)',
fontsize=14, fontweight='bold')
ax.set_axis_off()
plt.tight_layout()
plt.show()
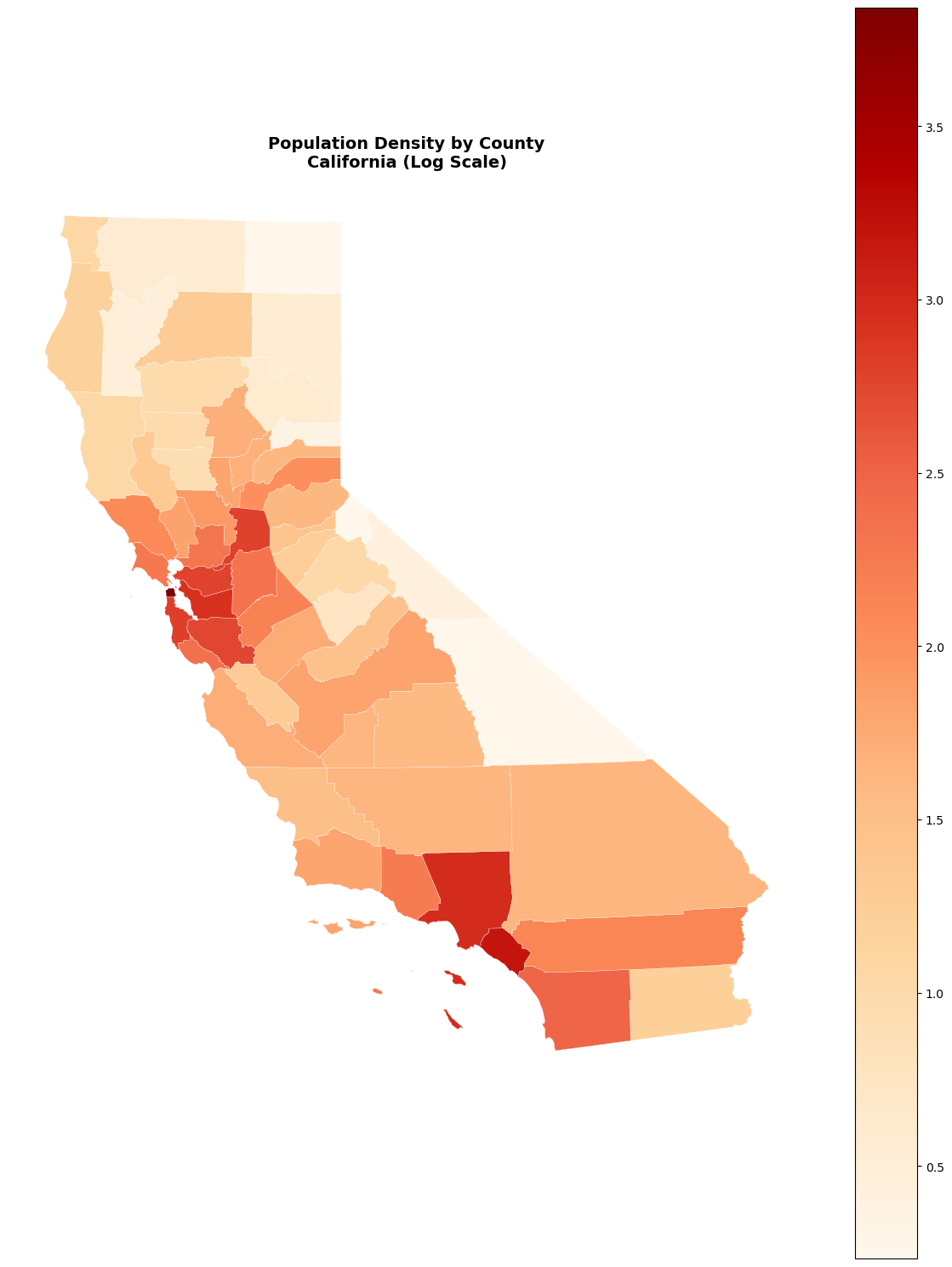
Advanced Visualization Techniques
Using Different Color Schemes
# Compare different color schemes
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
axes = axes.ravel()
cmaps = ['viridis', 'plasma', 'RdYlBu_r', 'coolwarm']
titles = ['Viridis', 'Plasma', 'RdYlBu_r', 'Coolwarm']
for i, (cmap, title) in enumerate(zip(cmaps, titles)):
ca_counties_proj.plot(
column="log_density",
cmap=cmap,
linewidth=0.1,
edgecolor="white",
legend=True,
ax=axes[i],
)
axes[i].set_title(f'{title} Color Scheme', fontweight='bold')
axes[i].set_axis_off()
plt.suptitle('Median Household Income - Different Color Schemes\nOrange County, CA',
fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()
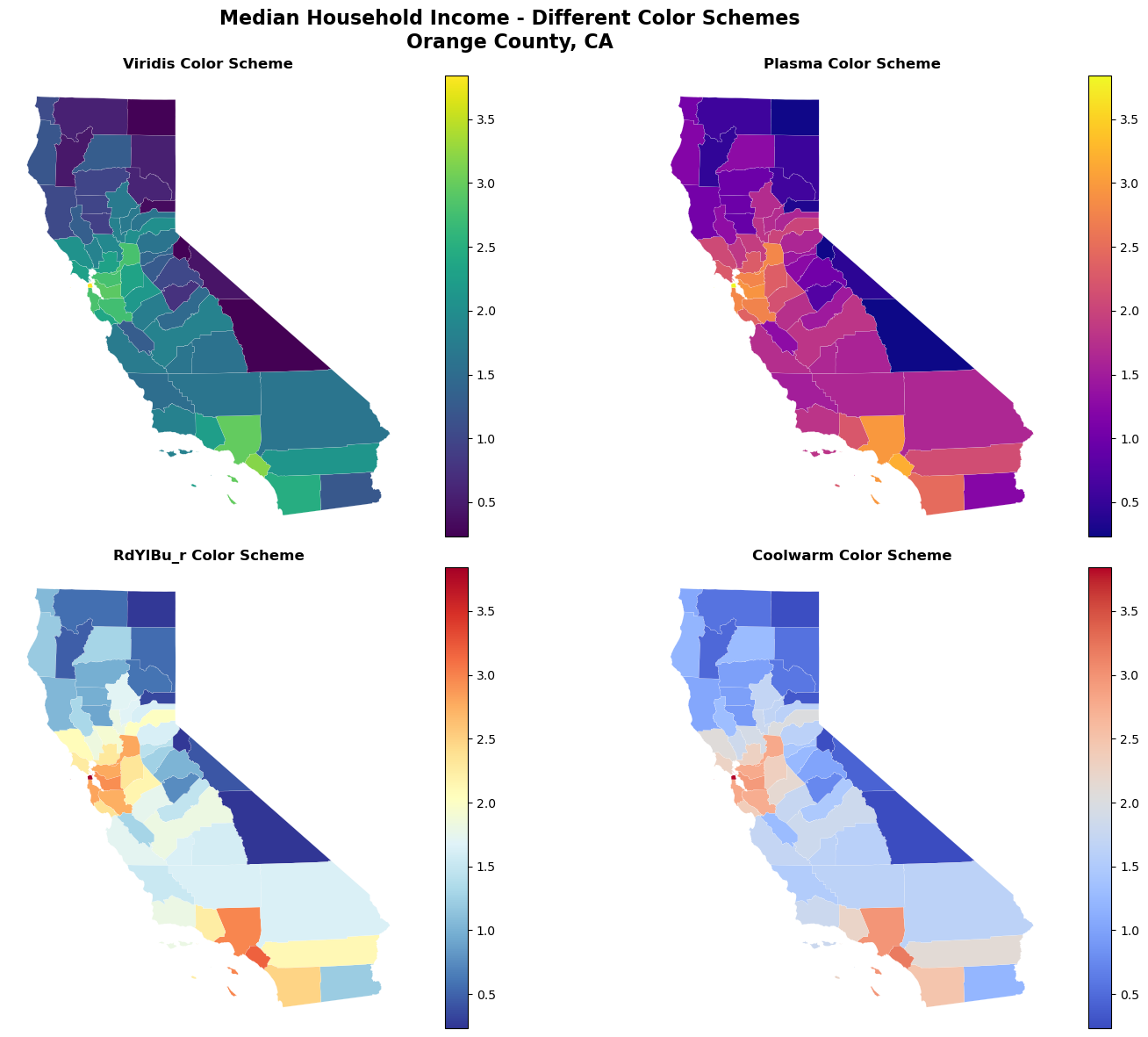
Classification Schemes
Sometimes it’s useful to classify continuous data into discrete categories:
# Create income categories
orange_classified = orange_projected.copy()
orange_classified.dropna(subset=["B19013_001E"], inplace=True)
# Define income brackets
bins = [0, 50000, 75000, 100000, 150000, float('inf')]
labels = ['< $50K', '$50K-$75K', '$75K-$100K', '$100K-$150K', '> $150K']
orange_classified["income_category"] = pd.cut(
orange_classified["B19013_001E"], bins=bins, labels=labels, include_lowest=True
)
# Create custom color palette
colors = ['#fee5d9', '#fcbba1', '#fc9272', '#fb6a4a', '#de2d26']
from matplotlib.patches import Patch
# Create legend handles for each category
legend_handles = [
Patch(facecolor=color, edgecolor="white", label=label)
for label, color in zip(labels, colors)
]
fig, ax = plt.subplots(figsize=(12, 10))
for category, color in zip(labels, colors):
subset = orange_classified[orange_classified["income_category"] == category]
subset.plot(color=color, linewidth=0.1, edgecolor="white", ax=ax)
ax.set_title(
"Median Household Income Categories\nOrange County, CA",
fontsize=14,
fontweight="bold",
)
ax.set_axis_off()
ax.legend(
handles=legend_handles,
title="Income Category",
loc="upper left",
bbox_to_anchor=(1, 1),
)
plt.tight_layout()
plt.show()
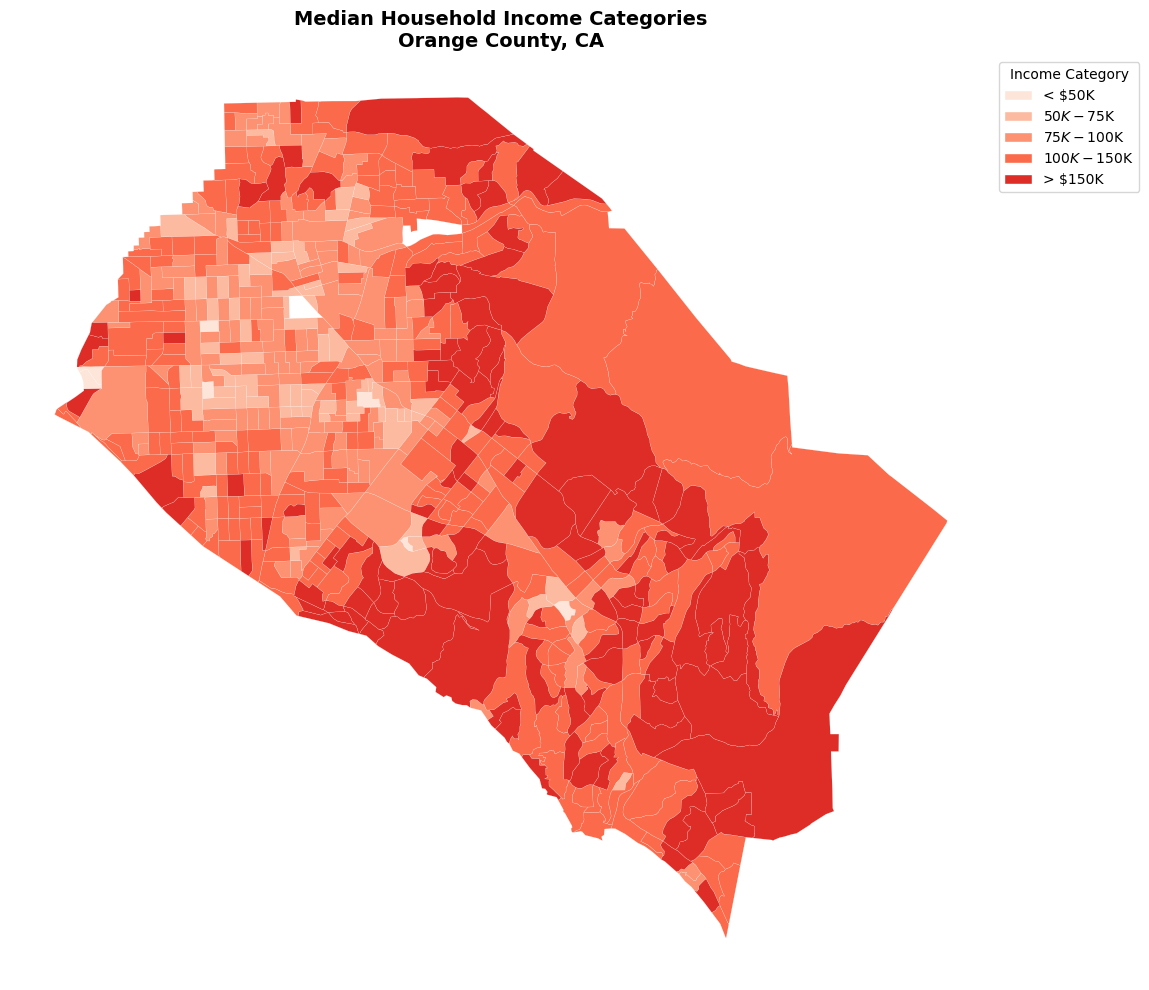
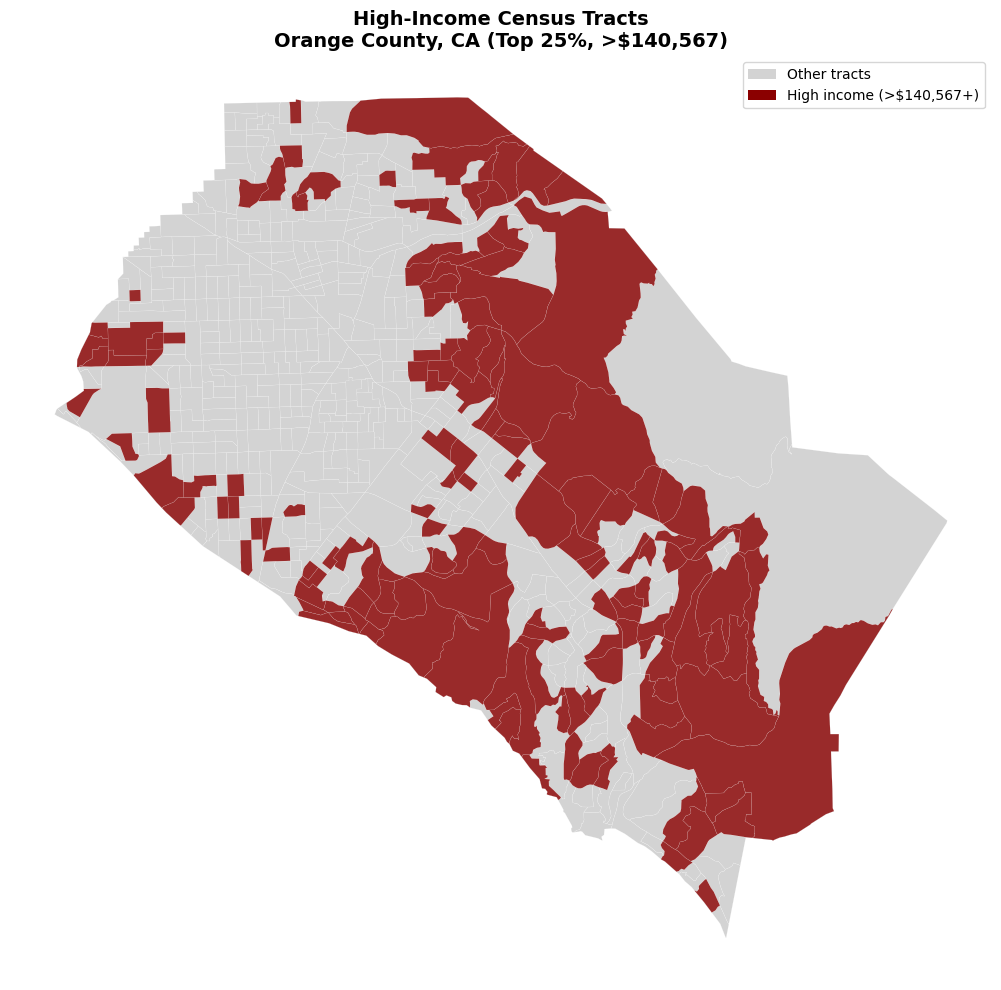
Spatial Analysis
Let’s perform some basic spatial analysis:
# Calculate centroids and identify high-income clusters
orange_analysis = orange_projected.copy()
orange_analysis['centroid'] = orange_analysis.geometry.centroid
# Identify high-income tracts (top quartile)
high_income_threshold = orange_analysis["B19013_001E"].quantile(0.75)
orange_analysis["high_income"] = orange_analysis["B19013_001E"] >= high_income_threshold
print(f"High income threshold: ${high_income_threshold:,.0f}")
print(f"Number of high-income tracts: {orange_analysis['high_income'].sum()}")
print(f"Percentage of tracts: {100 * orange_analysis['high_income'].mean():.1f}%")
High income threshold: $140,567
Number of high-income tracts: 153
Percentage of tracts: 25.0%
# Visualize high-income areas
fig, ax = plt.subplots(figsize=(12, 10))
# Plot all tracts in light gray
orange_analysis.plot(
color='lightgray',
linewidth=0.1,
edgecolor='white',
ax=ax
)
# Highlight high-income tracts
high_income_tracts = orange_analysis[orange_analysis['high_income']]
high_income_tracts.plot(
color='darkred',
linewidth=0.1,
edgecolor='white',
ax=ax,
alpha=0.8
)
ax.set_title(f'High-Income Census Tracts\nOrange County, CA (Top 25%, >${high_income_threshold:,.0f})',
fontsize=14, fontweight='bold')
ax.set_axis_off()
# Add legend
from matplotlib.patches import Patch
legend_elements = [
Patch(facecolor='lightgray', label='Other tracts'),
Patch(facecolor='darkred', label=f'High income (>${high_income_threshold:,.0f}+)')
]
ax.legend(handles=legend_elements, loc='upper right')
plt.tight_layout()
plt.show()
Summary Statistics by Geography
Let’s compute some summary statistics for our spatial data:
# Summary statistics for Orange County income data
print("Median Household Income Statistics - Orange County, CA")
print("=" * 55)
print(f"Mean: ${orange['B19013_001E'].mean():,.0f}")
print(f"Median: ${orange['B19013_001E'].median():,.0f}")
print(f"Std Dev: ${orange['B19013_001E'].std():,.0f}")
print(f"Min: ${orange['B19013_001E'].min():,.0f}")
print(f"Max: ${orange['B19013_001E'].max():,.0f}")
print(f"Range: ${orange['B19013_001E'].max() - orange['B19013_001E'].min():,.0f}")
# Quartile analysis
print("\nQuartile Analysis:")
quartiles = orange["B19013_001E"].quantile([0.25, 0.5, 0.75])
for q, val in quartiles.items():
print(f"{int(q*100)}th percentile: ${val:,.0f}")
Median Household Income Statistics - Orange County, CA
=======================================================
Mean: $117,036
Median: $112,780
Std Dev: $40,207
Min: $36,441
Max: $250,001
Range: $213,560
Quartile Analysis:
25th percentile: $85,860
50th percentile: $112,780
75th percentile: $140,567
Saving Spatial Data
You can save your spatial data in various formats:
# Save to different formats (uncomment to save)
# orange.to_file("orange_county_income.shp") # Shapefile
# orange.to_file("orange_county_income.geojson", driver="GeoJSON") # GeoJSON
# orange.to_parquet("orange_county_income.parquet") # Parquet (preserves geometry)
print("File formats available for saving:")
print("- Shapefile (.shp)")
print("- GeoJSON (.geojson)")
print("- Parquet (.parquet)")
print("- PostGIS database")
print("- And many more via GeoPandas!")
File formats available for saving:
- Shapefile (.shp)
- GeoJSON (.geojson)
- Parquet (.parquet)
- PostGIS database
- And many more via GeoPandas!
Summary
In this notebook, we learned how to:
Get spatial data by setting
geometry=Truein pytidycensus functionsCreate choropleth maps using GeoPandas and matplotlib
Work with coordinate systems and projections
Create faceted maps for comparing multiple variables
Use different visualization techniques including color schemes and classification
Perform basic spatial analysis like identifying spatial patterns
Save spatial data in various formats
Next Steps
Advanced Spatial Analysis: Use spatial statistics packages like
PySALInteractive Maps: Create web maps with
foliumorplotly3D Visualization: Use packages like
pydeckfor 3D mappingWeb Mapping: Deploy maps with
streamlitordash